Stages of AI Tuning
The world of AI customization involves a spectrum of approaches ranging from zero-cost prompt engineering to fully-fledged pre-training of large language models (LLMs) from scratch. Each stage offers varying levels of complexity, data requirements, and organizational investment. Understanding these stages can help you choose the right approach for your specific business or research needs.
Overview of the Stages
The main strategies for tuning or customizing an AI model include:
-
Prompt Engineering
At the simplest end of the spectrum lies prompt engineering. Instead of altering the model’s parameters, you craft carefully worded prompts to guide the model’s outputs. This approach requires no additional data or lengthy training sessions. It’s quick, cost-effective, and provides immediate improvements, but offers less fine-grained control. -
Retrieval Augmented Generation (RAG)
RAG introduces external knowledge sources—such as a vector database or an up-to-date knowledge base—into the model’s responses. By retrieving relevant information at query time, the model can deliver more accurate and contextually rich answers without retraining. While it increases complexity and inference costs, RAG remains a powerful method to dynamically update the model’s “knowledge” on the fly. -
Fine-Tuning
For organizations seeking more specialized control, fine-tuning is the next level. By training a pre-existing LLM on your domain-specific data, you can refine its behavior and outputs. Although it requires labeled data, computational resources, and a more extended training period than prompt engineering or RAG, fine-tuning grants granular control over the model’s performance and can significantly improve domain-specific accuracy. -
Pre-Training
At the most resource-intensive end of the spectrum is pre-training an LLM from scratch on massive datasets. This approach provides maximum control and a tailor-made model architecture perfectly aligned with your unique needs. However, it demands significant time (often weeks or months), computational power, and large-scale curated data. It’s typically pursued by large organizations or research teams aiming for pioneering innovations.
Visualizing the Spectrum
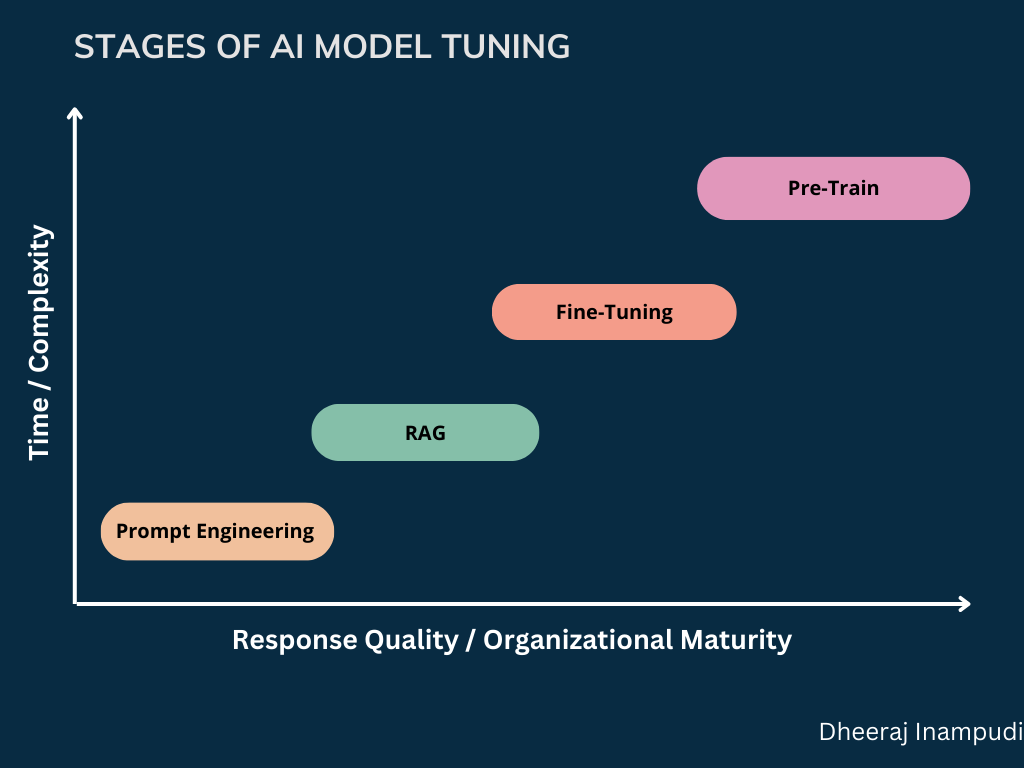
for a visual illustration of these stages plotted against factors like Time/Complexity and Response Quality/Organizational Maturity. As you move from Prompt Engineering to RAG, and then on to Fine-Tuning, and finally Pre-Training, both the resource investment and level of achievable specificity increase.
Detailed Comparison
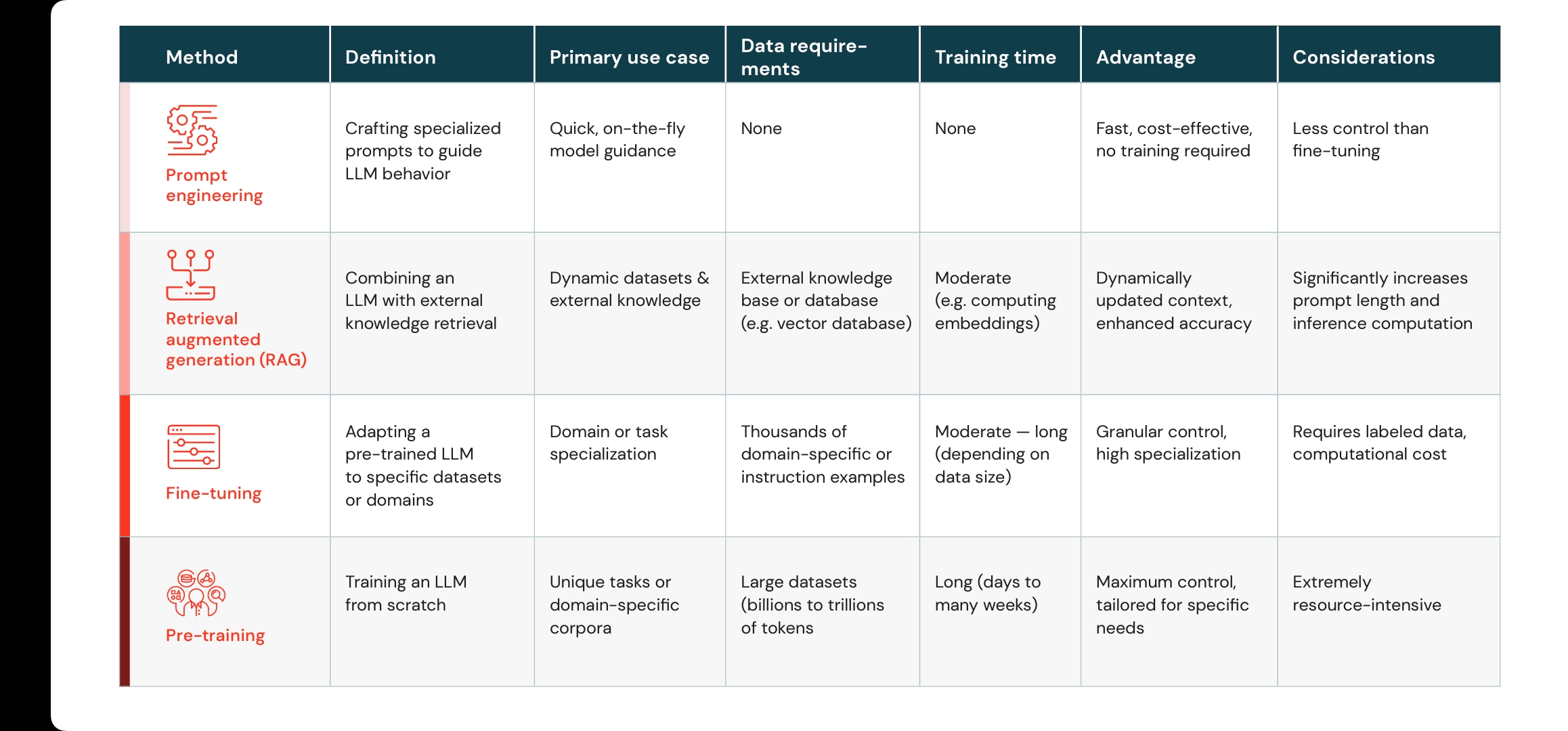 |
|---|
| Sourced from Databricks blog |
provides a detailed table of these methods, highlighting key attributes such as:
-
Data Requirements:
- Prompt Engineering: None
- RAG: External knowledge base
- Fine-Tuning: Thousands of domain-specific samples
- Pre-Training: Billions to trillions of tokens
-
Training Time:
- Prompt Engineering: None
- RAG: Moderate (e.g., computing embeddings)
- Fine-Tuning: Moderate to long (depending on dataset size)
- Pre-Training: Long (days to many weeks)
-
Advantages and Considerations:
- Prompt Engineering: Fast and cost-effective, but limited control.
- RAG: Dynamically updated context, but longer prompts and increased inference costs.
- Fine-Tuning: Granular domain specialization, but requires labeled data and more compute.
- Pre-Training: Maximum control and tailor-fit, but extremely resource-intensive.
Choosing the Right Approach
Selecting the right stage of AI tuning depends on your organization’s goals, resources, and maturity level:
- Immediate Results, No Additional Data: Prompt Engineering
- Dynamic Knowledge Integration: Retrieval Augmentation
- Specific Domain Expertise: Fine-Tuning
- Full Control & Customization: Pre-Training
By understanding each stage’s trade-offs, you can strategically invest in the approach that best aligns with your constraints and aspirations.